WHAT IS CNN? (CONVOLUTIONAL NEURAL NETWORKS)
Have you ever wondered how intelligent systems recognize objects, entities from images and videos ?
In this lesson we would cover:
- Pin hole camera and How images are formed
- Linear Transformations & Neural Networks
- Internal workings of CNN
- Implement a mini Image Classifier in pytorch
How Images are Formed
A pin-hole camera is a lensless camera, that consists of a light-proof box and a small hole(Aperture). Light Passes through the hole and and Inverted Image of the scene is projected at the back of the box.
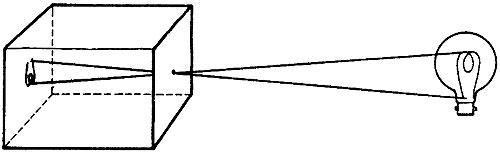
A pin-hole camera
In New and Advanced Cameras They come with lenses, and advanced sensors that make image projected and colour mapping as close as possible to real-world scenarios, but they are all built upon the same core operating principles of a pin-hole camera.
A camera maps 3D world coordinates to 2D Planes, using the given mathematical relationship:
where:
x = 2D coordinates of camera
K = Intrinsic parameters of camera
R = Rotation matrices of camera (3 x 3)
T = Translation matrices of camera (3 x 1)
X = 3D world coordinates (3 x 1)
where (u, v) represents 2d coordinates of a single pixel(RGB or grey scale) on a 2d image.
Linear Transformations & Neural networks
A linear Transformation is a function that maps one vector space to another, while preserving the operations of vector addition & scalar multiplication. Geometrically, it only alters the length and rotation, but never alters the origin and linearity of the line.
A transformation T can only be called linear if:
Neural Networks are essentially built by stacking and combining multiple linear transformations , but they add non-linear activation functions when modelling non-linear problems to complex real-world problems.
While Linear Transformations can only solve direct linear problems i.e when the data points just evolve on one straight line, Neural Networks can solve non-linear problems because it can bend, curve and adapt a line to the data points.
Internal Workings of CNN
Convolutional Neural Networks are special type of neural networks that extract local features from an input image or frames of videos by applying a fixed sliding matrix to extract important features from each pixel, Unlike standard neural networks that flatten an image into a single list of pixels, CNNs preserve the spatial relationships between pixels by using a mathematical operation called convolution.
How it Works
-
Feature Extraction: This layer passes a small learnable square matrix called kernels across the input image. The kernel slides across each windows using a parameter called strides, the strides controls how much step the kernel takes from the previous window to the next window. As the Kernel slides across the image, it performs an element-wise multiplication and sums the results. which produces a feature map that detects edges, textures and shapes in the image.
-
Activation Layer: This Layer adds a non-linear activation function to the feature maps, This replaces all negative pixel values with 0, allowing the network to learn complex and non-linear patterns
-
Pooling Layer : This layers reduces the spatial size of the feature maps, to cut-down computation costs of high-dimensional spatial features. There are two methods of pooling: Average pooling & Max Pooling, What pooling does is that it moves a sliding window over the feature maps and perform either the average or maximum of the values within that window(pool).
Imagine a small patch of an Image I represented as 3 x 3 matrix, and a 3 x 3 kernel K :
therefore, the element-wise multiplication would be computed as :
value of this position, on the feature map would be computed as :
Mini Implementation of a Conv Classifier in Pytorch
import torch
from torch import nn
class ConvNetwork(nn.Module):
def __init__(self, dim_in: int , dim_out: int ,
kernel_size: int ,stride : int = 1,
hidden_dim: int = 256):
super().__init__()
self.dim_in = dim_in
self.dim_out = dim_out
self.kernel_size = kernel_size
self.stride = stride
self.adaptive_pool = nn.AdaptiveAvgPool2d((1, 1))
self.hidden_dim = hidden_dim
self.conv1 = nn.Conv2d(in_channels = dim_in ,
out_channels = hidden_dim,
kernel_size = kernel_size,
stride = stride)
self.conv2 = nn.Conv2d(in_channels = hidden_dim ,
out_channels = hidden_dim,
kernel_size = kernel_size,
stride = stride)
self.linear = nn.Linear(hidden_dim, dim_out)
def forward(self, x):
y = self.conv1(x)
y = self.conv2(y)
y = self.adaptive_pool(y)
y = self.linear(y.flatten(1))
y = torch.argmax(y , dim=-1)
return y
In this Mini implementation, We see that network takes in some parameters which are:
- dim_in : Represents the number of channels of the input image, either 3 for colored images or 1 for grayscale images
- dim_out: Represents the number of classes we are trying to classify
- kernel_size: Represents the dimension of the sliding filter that extracts featured from the input image
##Try yourself
conv_net = ConvNetwork(dim_in = 3 , dim_out = 7 , kernel_size = 1)
test_image = torch.rand([1,3,256,512])
output_class = conv_net(test_image)
Next Steps
This video from computerphile might give you a more clearer picture of this tutorial and what we would cover in the future.
In this Tutorial, we covered how images are formed from the camera, how world coordinates are mapped to pixel-level coordinates and how to classifier images using CNNs. In our Next Tutorials we would cover more into videos, 3D computer vision and scene reconstruction from pixel coordinates.